Day 37 Task: Kubernetes Important interview Questions.
Hey there! I am Rohit !! I started writing articles on my DevOps and cloud journey👩🏻💻. My purpose is to share the concepts that I learn, the projects that I build, and the tasks that I perform regarding DevOps. Welcome to my blog!!
What is Kubernetes and why it is important?
Kubernetes is an open-source container orchestration platform that automates the deployment, scaling, and management of containerized applications. It allows organizations to run and manage containers at scale in a distributed environment.
Kubernetes enables efficient scaling of applications by automatically distributing containers across a cluster of machines.
It ensures high availability by automatically restarting or rescheduling containers in case of failures.
Kubernetes provides built-in service discovery and load balancing, simplifying communication between containers.
It supports automated rollouts and rollbacks, making it easy to deploy and update application versions.
Kubernetes optimizes resource utilization by packing containers onto nodes based on their requirements.
It can autoscale the number of nodes in a cluster, adapting to workload demands and resource availability.
Kubernetes offers portability, allowing applications to run on different infrastructure providers.
It simplifies the management of containerized applications, reducing operational complexity.
Kubernetes fosters the adoption of microservices architecture, enabling modular and scalable application development.
It is a widely adopted industry standard, supported by a vibrant community, and offers a rich ecosystem of tools and integrations.
What is the difference between docker swarm and Kubernetes?
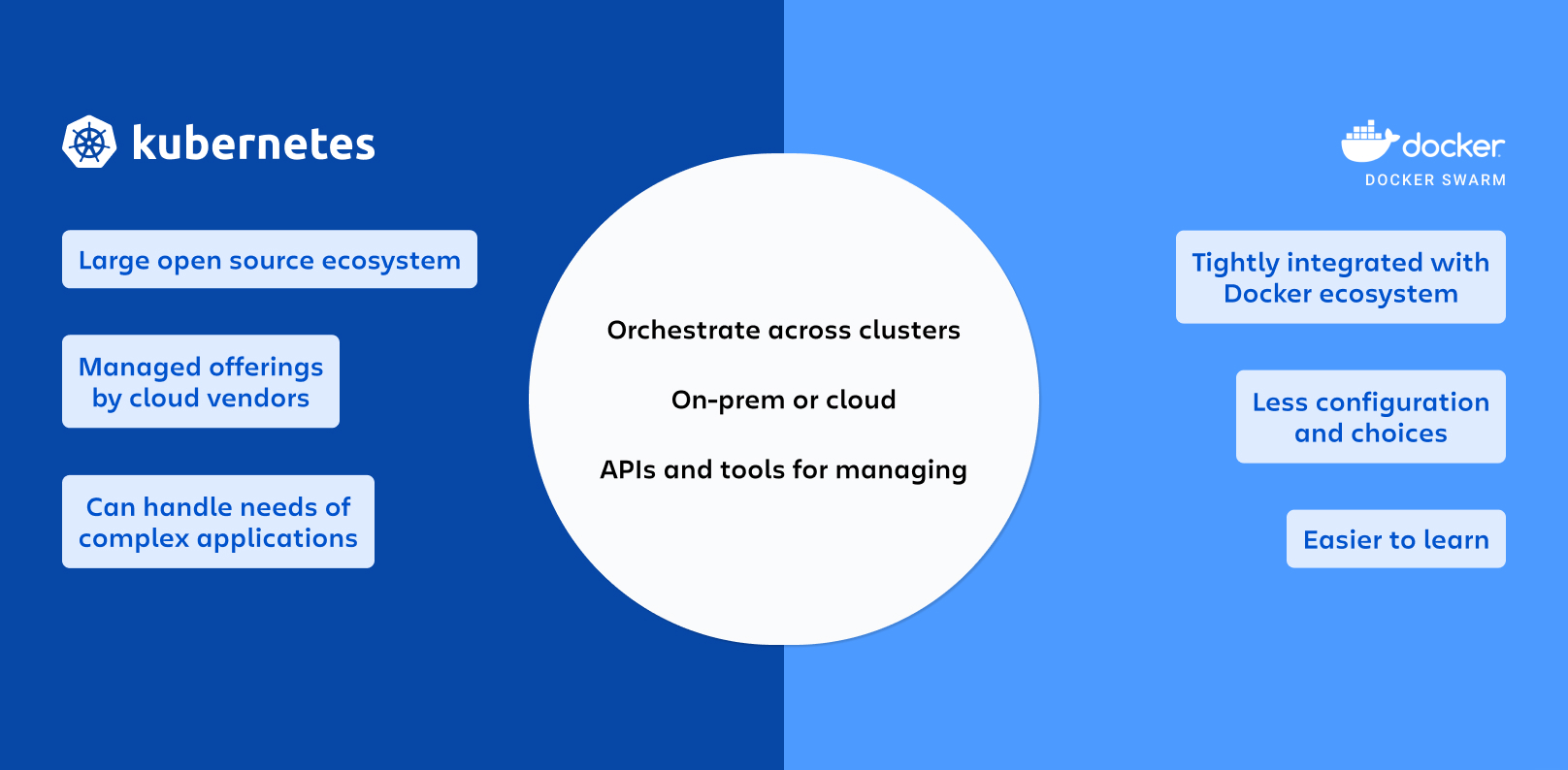
Here are the key differences between Docker Swarm and Kubernetes:
Architecture: Docker Swarm is tightly integrated with Docker and uses the Docker Engine, while Kubernetes is a standalone platform that can work with various container runtimes.
Features: Docker Swarm provides a simpler set of features for container orchestration, while Kubernetes offers a more extensive set of advanced features like scaling, rolling updates, and storage orchestration.
Scalability: Kubernetes is known for its ability to handle complex and large-scale deployments, making it suitable for enterprise-grade workloads, whereas Docker Swarm is better suited for smaller-scale deployments.
Community and Ecosystem: Kubernetes has a larger and more vibrant community, with a wide range of third-party tools, plugins, and integrations available. Docker Swarm has a smaller community and a more limited ecosystem.
Adoption: Kubernetes has become the de facto standard for container orchestration and has gained widespread adoption in the industry, while Docker Swarm has a smaller user base.
How does Kubernetes handle network communication between containers?
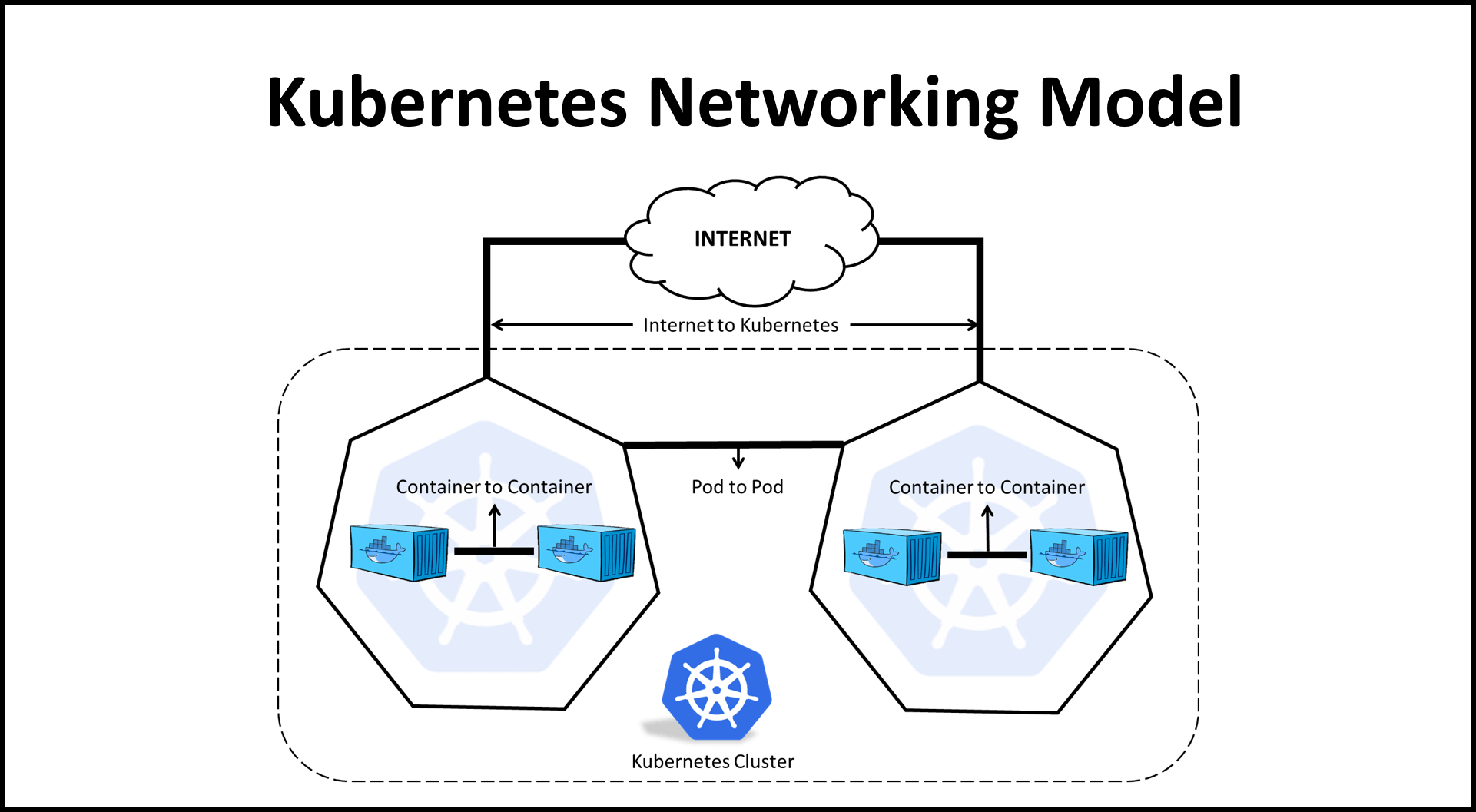
Pod Networking: Containers within a pod share the same network namespace and can communicate with each other using localhost. Each pod gets a unique IP address.
Service Networking: Kubernetes assigns a stable IP address and DNS name to a set of pods, known as a service, allowing other pods or services to communicate with it using the service's IP or DNS name.
Cluster Networking: Kubernetes uses a cluster-level network overlay to enable communication between pods across different nodes in the cluster. This allows pods to communicate with each other seamlessly, regardless of their physical location.
Network Plugins: Kubernetes supports various network plugins that implement the cluster network overlay, such as Flannel, Calico, or Weave. These plugins manage the virtual network and handle routing and traffic management within the cluster.
Ingress and Load Balancing: Kubernetes provides Ingress resources and Load Balancer services to route external traffic to pods or services, allowing communication with applications running in the cluster from outside the cluster.
How does Kubernetes handle the scaling of applications?

Kubernetes handles the scaling of applications through the following mechanisms:
Horizontal Pod Autoscaling (HPA): Kubernetes allows you to define autoscaling rules based on CPU utilization, memory consumption, or custom metrics. It automatically adjusts the number of replicas of a pod to meet the defined criteria.
Vertical Pod Autoscaling (VPA): VPA automatically adjusts the resource limits and requests of containers based on their actual usage, optimizing resource allocation within each pod.
Cluster Autoscaling: Kubernetes can automatically scale the number of nodes in a cluster based on resource demands. It ensures that sufficient resources are available to accommodate the scaling requirements of the applications running in the cluster.
Manual Scaling: Kubernetes provides a simple interface to manually scale the number of replicas for deployment or stateful set. You can easily adjust the desired number of replicas to increase or decrease the application's capacity.
Custom Metrics and External Tools: Kubernetes allows you to integrate with external metrics systems and custom metrics to drive scaling decisions. You can define your own metrics and use them to trigger scaling actions based on specific application requirements.
What is a Kubernetes Deployment and how does it differ from a ReplicaSet?
A Kubernetes Deployment is a higher-level resource that manages the lifecycle of a set of pods and provides declarative updates and rollbacks. It ensures the desired number of replicas of a pod template is running, manages to scale, and performs rolling updates.
A ReplicaSet, on the other hand, is a lower-level resource that ensures a specified number of replicas of a pod template are running at all times. It does not support rolling updates or rollbacks.
In summary, a Deployment provides more advanced features for managing application deployments, such as rolling updates and rollbacks, while a ReplicaSet focuses solely on maintaining a specified number of replicas. Deployments build on top of ReplicaSets to provide additional functionality.
Can you explain the concept of rolling updates in Kubernetes?

Rolling updates in Kubernetes are a strategy for updating applications running in a cluster without causing downtime. It involves gradually replacing old instances of an application with new ones, ensuring a smooth transition.
Kubernetes achieves this by creating new instances of the updated application while keeping the existing ones running. It then gradually directs traffic to the new instances and terminates the old ones, ensuring uninterrupted service availability.
This approach provides a seamless and controlled way to update applications, allowing for easy rollback if any issues arise during the update process.
How does Kubernetes handle network security and access control?
Kubernetes handles network security and access control through the following mechanisms:
Network Policies: Kubernetes supports Network Policies to define rules for network traffic within the cluster. These policies enforce access control, allowing administrators to specify which pods can communicate with each other based on labels and namespaces.
Service Accounts: Kubernetes uses Service Accounts to authenticate and authorize pods and applications within the cluster. Each pod is associated with a Service Account, which grants it specific permissions and restricts its access to resources.
Role-Based Access Control (RBAC): Kubernetes implements RBAC to control access to cluster resources. RBAC allows administrators to define roles and assign them to users or groups, determining what actions they can perform within the cluster.
Secrets Management: Kubernetes provides a built-in mechanism for securely storing and managing sensitive information such as credentials or API keys. Secrets are encrypted and can be accessed only by authorized pods or applications.
Container Isolation: Kubernetes leverages container runtime features, such as Linux namespaces and control groups (cgroups), to enforce process-level isolation and resource constraints. This isolation helps prevent unauthorized access or interference between containers running on the same node.
Can you give an example of how Kubernetes can be used to deploy a highly available application?
Here's an example of how Kubernetes can be used to deploy a highly available application:
Deployment: Create a Kubernetes Deployment resource with multiple replicas of your application. This ensures that there are multiple instances of your application running to handle traffic and provide redundancy.
Load Balancing: Configure a Kubernetes Service resource to distribute traffic evenly among the replicas of your application. This provides load balancing and ensures that traffic is routed to healthy instances.
Health Checks: Set up health checks within the application to inform Kubernetes of its readiness and liveness. Kubernetes can use these health checks to determine the availability of the application and automatically handle failures.
Self-healing: Enable Kubernetes' self-healing capabilities. If a replica or node fails, Kubernetes will automatically restart or reschedule the application's instances to maintain the desired number of replicas and ensure high availability.
Cluster-level Redundancy: Deploy the Kubernetes cluster across multiple nodes or availability zones to ensure that the failure of a single node does not impact the availability of the application. This provides resilience and fault tolerance.
By following these steps, Kubernetes can help deploy and manage a highly available application by distributing traffic, handling failures, and ensuring that the desired number of replicas are running at all times.
What is a namespace in Kubernetes? Which namespace any pod takes if we don't specify any namespace?
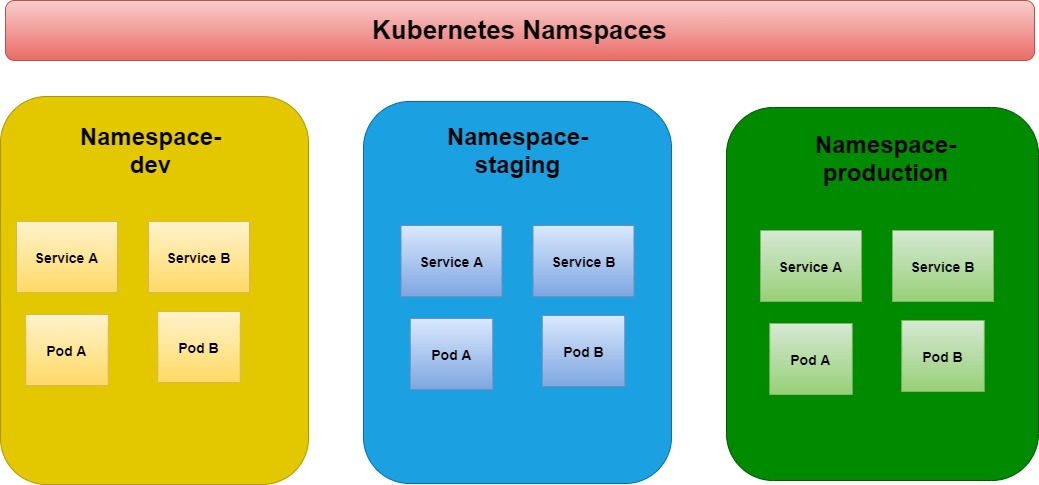
In Kubernetes, a namespace is a virtual cluster that provides a way to divide and isolate resources within a cluster. It acts as a logical boundary, allowing different teams or projects to have their own separate environments and resources without interfering with each other.
If a pod is not explicitly assigned to a namespace, it is automatically placed in the default namespace. The default namespace is created automatically when the Kubernetes cluster is set up, and it is where resources are created if no specific namespace is specified. It is common for small deployments or when working with a single team/project to use the default namespace.
However, it is recommended to use namespaces to organize and isolate resources as the number of deployments and complexity increases.
How does ingress help in Kubernetes?
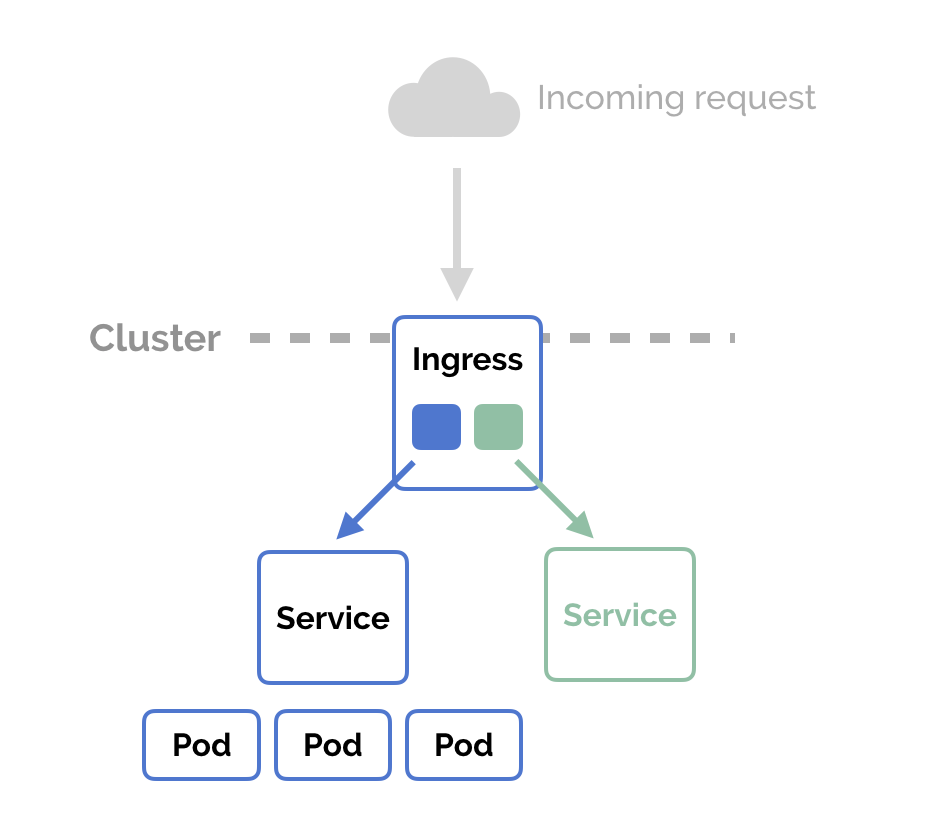
In Kubernetes, Ingress is an API object that provides a way to expose HTTP and HTTPS routes from outside the cluster to services within the cluster. It acts as a gateway or entry point that manages external access to services running inside the cluster. Here's how Ingress helps in Kubernetes:
External Traffic Routing: Ingress allows you to define rules and configure routing for incoming traffic from outside the cluster. It acts as a layer 7 load balancer, directing traffic to the appropriate service based on the specified rules, such as hostname or URL path.
Service Discovery: Ingress provides a way to discover and access services running inside the cluster from outside. It abstracts the underlying services and allows you to expose multiple services behind a single external IP address or domain.
SSL Termination and TLS Certificate Management: Ingress supports SSL termination, allowing you to terminate SSL/TLS encryption at the Ingress controller. It can handle TLS certificate management, including obtaining, renewing, and applying SSL certificates for secure communication.
URL-Based Routing and Path Rewriting: Ingress allows you to define URL-based routing rules, redirect requests to different services based on the URL path, and perform path rewriting. This enables advanced routing and customization of incoming requests.
Load Balancing: Ingress can distribute incoming traffic across multiple backend services, providing load-balancing capabilities. It helps distribute the workload evenly and ensures high availability and scalability of services.
Overall, Ingress simplifies the management of external access to services within a Kubernetes cluster, providing a flexible and configurable way to route traffic, handle SSL/TLS encryption, and manage service discovery.
Explain different types of services in Kubernetes.

In Kubernetes, there are different types of services available to facilitate communication and network connectivity between pods and external resources. Here are the commonly used types of services:
ClusterIP: ClusterIP is the default service type in Kubernetes. It provides internal access to services within the cluster. The service is assigned a stable IP address within the cluster, allowing other pods within the cluster to communicate with it.
NodePort: NodePort exposes a service on a specific port on each worker node in the cluster. It allows external access to the service by forwarding traffic from the specified port on each node to the service. It is typically used for development or testing purposes.
LoadBalancer: LoadBalancer provisions an external load balancer that distributes traffic to the service. It automatically assigns an external IP address, allowing traffic to be routed from outside the cluster to the service. This type of service is often used in cloud environments that support external load balancers.
ExternalName: ExternalName is used to create a service that maps to an external DNS name. It provides a way to access an external resource or service by using the DNS name instead of an IP address. It does not perform any proxying or routing and is mainly used for integrating with external systems.
Headless: Headless services are used when you want to directly communicate with individual pods instead of load balancing across replicas. It returns the IP addresses of the pods associated with the service rather than a single IP. It is useful for certain distributed applications or stateful sets.
These different service types in Kubernetes offer flexibility in managing network connectivity and access to services, allowing for internal and external communication with pods and external resources.
Can you explain the concept of self-healing in Kubernetes and give examples of how it works?
Self-healing in Kubernetes refers to the ability of the platform to automatically detect and recover from failures or deviations in the desired state. Examples of self-healing mechanisms include:
Pod Restarts: Kubernetes automatically restarts pods that fail or become unresponsive, ensuring the application remains available.
Node Failure Handling: If a node fails, Kubernetes redistributes the affected pods to healthy nodes, maintaining application availability.
ReplicaSet Management: Kubernetes monitors the desired number of replicas and automatically creates or terminates pods to maintain the desired state.
Service Discovery: Kubernetes continually monitors the health of services and removes unhealthy instances from the pool, preventing traffic from being routed to them.
Rolling Updates and Rollbacks: Kubernetes supports rolling updates, gradually replacing old instances with new ones, and rollbacks in case of issues during updates, ensuring smooth application upgrades.
How does Kubernetes handle storage management for containers?
Kubernetes handles storage management for containers through the following mechanisms:
Persistent Volumes (PV): Kubernetes abstracts underlying storage systems using PVs, allowing administrators to provision storage and define its characteristics, such as capacity and access modes.
Persistent Volume Claims (PVC): Users can request storage resources using PVCs, which bind to available PVs based on matching criteria such as capacity and access modes. PVCs provide a way for applications to dynamically request and consume storage.
Storage Classes: Storage Classes define different classes of storage with varying performance and availability characteristics. Users can request storage from specific storage classes, allowing for flexibility and differentiation in storage provisioning.
Volume Plugins: Kubernetes supports various volume plugins that interface with different storage systems, enabling the use of different storage technologies such as local disks, network-attached storage (NAS), or cloud storage.
Dynamic Provisioning: Kubernetes can dynamically provision PVs and associated storage resources based on PVC requests, eliminating the need for manual provisioning. This enables efficient utilization and on-demand storage allocation.
Through these mechanisms, Kubernetes provides a flexible and scalable approach to storage management, allowing containers and applications to consume and utilize storage resources efficiently and seamlessly.
How does the NodePort service work?
The NodePort service in Kubernetes exposes a service on a specific port across all worker nodes in the cluster. It maps the specified port to the service's target port. Incoming traffic on the assigned NodePort is forwarded to the service, which then load balances it among the pods.
It allows external access to the service using any node's IP address and the assigned NodePort. NodePort is mainly used for development or testing purposes and is not recommended for production environments due to security concerns.
What is a multinode cluster and a single-node cluster in Kubernetes?
In Kubernetes, a multinode cluster refers to a setup where multiple worker nodes are connected to form a cluster. Each worker node in the cluster runs the Kubernetes components and hosts pods, allowing for distributed computing and resource sharing. Multinode clusters are commonly used in production environments to achieve high availability, scalability, and fault tolerance.
On the other hand, a single-node cluster is a Kubernetes setup where all the Kubernetes components, including the control plane and worker nodes, run on a single machine or virtual machine. It is typically used for local development, testing, or learning purposes. A single-node cluster provides a simplified environment to experiment with Kubernetes features and deploy applications without the complexity of a larger cluster.
While single-node clusters are useful for learning and development, multinode clusters are preferred in real-world scenarios to harness the benefits of distributing workloads across multiple nodes and ensuring resilience and scalability.
Difference between creating and applying in Kubernetes?
Creating Resources: When you create a resource in Kubernetes, you are defining it for the first time. You provide the resource configuration in a YAML or JSON file and use the
kubectl createcommand followed by the file name to create the resource. This operation will create a new resource with the specified configuration.Applying Resources: When you apply a resource in Kubernetes, you are updating an existing resource with the provided configuration. You also provide the resource configuration in a YAML or JSON file, but you use the
kubectl applycommand followed by the file name to apply the changes. This operation will compare the desired state with the current state of the resource and make necessary updates or modifications to bring the resource in line with the desired state.The key distinction is that creating a resource is for initial creation, while applying a resource is for making updates or modifications to an existing resource. Applying ensures that the desired state of the resource is maintained, allowing for incremental changes and easy management of resources over time.
Conclusion
Kubernetes is the leading technology, and companies always look for skilled employees. To help you secure a job, we put some effort and listed some preferred topics in Kubernetes Interview Questions.
Thank you for reading!! I hope you find this article helpful......